Tsuyoshi UshioTop 10 Azure Functions Anti-PatternsI’ve often come across suboptimal practices related to Azure Functions. To streamline the information, I’ve highlighted the top 10 Azure…10 min read·Oct 18, 2023--1--1
Tsuyoshi UshioDistributed System Logging Best Practices (1) — OverviewI wanted to know the best practices how for writing logs. However, I can’t find the best practices for it. It might not be mature, however…3 min read·Jan 12, 2023----
Tsuyoshi UshioDistributed System Logging Best Practices (3) — AutomationWe use logging for automation. That saves a bunch of time especially if your team is working as DevOps model. Good logging practices help…3 min read·Jan 12, 2023--1--1
Tsuyoshi UshioDistributed System Logging Best Practices (2) — How to write logs?Described the importance of logging on to the previous post. This article shows the best practices for logging messages.7 min read·Jan 12, 2023----
Tsuyoshi UshioHow to solve sluggish Win11 issue when you RDP into itWhen I RDP into my machine, after upgrading to Win11, the first-time login was fine but second time, it gets sluggish. It was fixed by…2 min read·Dec 22, 2022----
Tsuyoshi UshioWriting a function with Action in PowerShellI wanted to write a function that has an action parameter. The goal is to write functions that have the following features:2 min read·Oct 3, 2022----
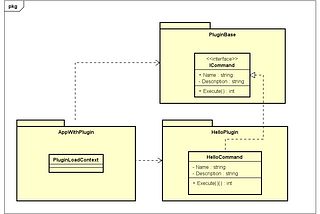
Tsuyoshi UshioUnderstand Advanced AssemblyLoadContext with C#I shared the fundamental of AssemblyLoadContext usage with the following Post. I’d like to plugin loading advanced. usages.5 min read·Jul 4, 2022----
Tsuyoshi UshioUnderstanding Dynamic Assembly Loading with AssemblyLoadContext in C#I encountered an issue that .NET Framework app reading a plugin in runtime. One person uses Library A, and the other uses Library B. Both…4 min read·Jul 4, 2022--1--1
Tsuyoshi UshioOption patterns with custom configuration provider in .NETHow to develop reloadable provider for Option Patterns6 min read·Jan 3, 2022----
Tsuyoshi UshioHow to get an opportunity of an innovative project from scratch?Many people working on add feature/improvement on legacy code. Not many people working on designing from scratch and write code for brand…3 min read·Aug 7, 2021----